
Evaluating AI-generated answers isn’t optional anymore. When agents power customer support, compliance checks, or internal knowledge tools, organizations must be able to prove their responses are accurate, relevant, and evidence‑grounded not just “good enough.”
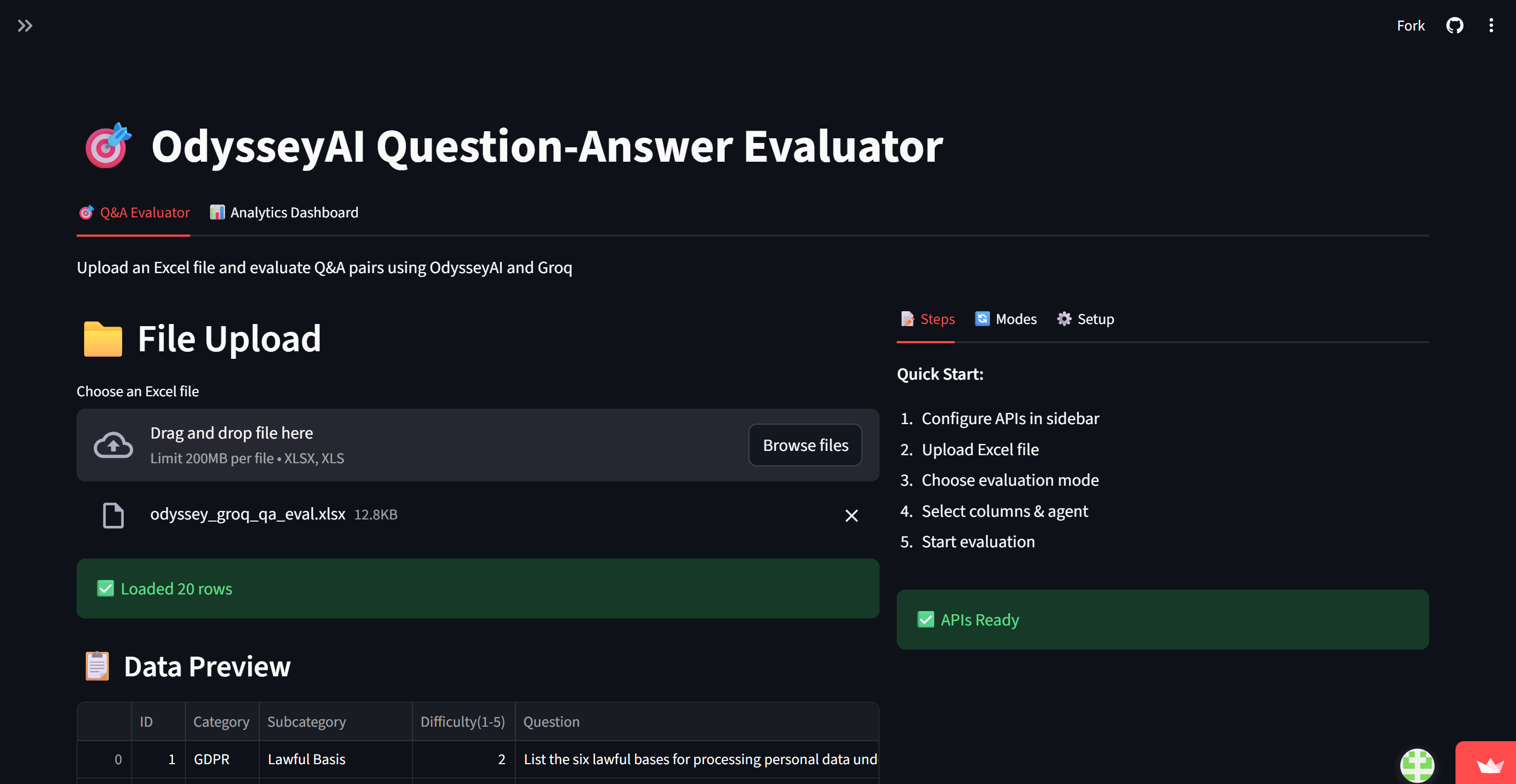
That’s where the Odyssey AI Question‑Answer Evaluator (QA Evaluator) comes in. Built by Inteligems, this web‑based tool automates large‑scale evaluation of question–answer pairs or standalone prompts using Odyssey AI agents. It applies a weighted multi‑criteria scoring framework with 14 detailed subchecks, delivering transparent, data‑backed insight into model quality.
Odyssey AI's QA Evaluator transforms manual, subjective QA review into structured, repeatable analysis.
It:
This means every evaluation produces verifiable proof of quality rather than anecdotal judgment.
Different teams rely on the QA Evaluator for complementary reasons:
Comparison Mode:
When you have ground‑truth answers, this mode compares the AI’s response to that truth and produces a Contextual Relevance Accuracy (CRA) score across accuracy, relevance, and completeness dimensions ideal for regression testing or A/B evaluations.
Criteria Mode:
When no reference answer exists, Criteria Mode evaluates open‑ended responses by five high‑level metrics such as faithfulness, clarity, nuance, and entity alignment perfect for exploratory use cases and early‑stage prototypes.
The QA Evaluator organizes 14 sub checks into six weighted categories:
Together, these produce a balanced evaluation that tracks the true quality of your AI outputs beyond surface correctness.
Odyssey AI’s QA Evaluator goes further than static scoring. It supports audit report generation, feedback ingestion, and RLHF‑aligned training loops.
Evaluations and user interactions thumbs up/down, session history, timestamps feed into analytics pipelines that surface recurring quality gaps. Future updates will merge these audit logs directly into the main dashboard for continuous improvement tracking and model reward tuning.

Want to see the system live?
Compared with frameworks like RAGAS, Vertex AI’s LLM Comparator, or Confident AI’s G‑Eval, Odyssey AI’s solution combines the benefits of multi‑mode scoring, Groq‑based performance, and governance‑ready evidence tracking all within the Odyssey platform.
It’s designed not just for benchmarking but for continuous assurance evaluating, improving, and defending deployed AI models with the same rigor as software QA.
Choose how to begin:
1. Download the Executable – Run locally without configuration or dependencies.
2. Use the Hosted App – Evaluate securely via the Odyssey AI web interface.
3. Clone the Open‑Source Repo – Integrate directly with your QA pipelines and Groq keys.
Most AI reviews stop at “that looks right.”
The Odyssey AI QA Evaluator goes further offering measurable, explainable evidence that your AI responses are accurate, contextual, and production‑ready.
When you need traceability, confidence, and speed in one place, this is how to turn quality from a guess into proof.
Product Updates

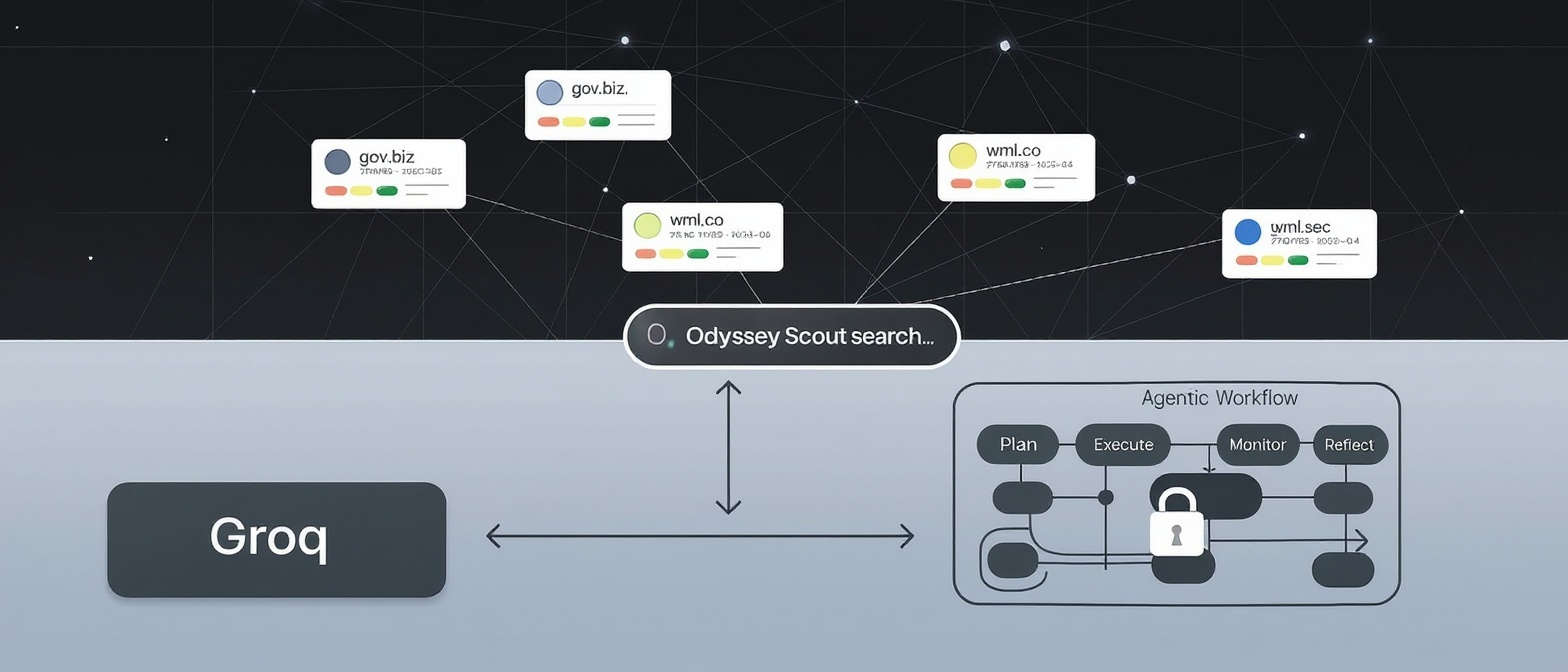
November 13, 2025
Odyssey Scout is a governed web research engine that enables AI agents to explore the live web while maintaining audit-ready compliance through policy-gated browsing, line-level SourceSnips™ citations, and exportable evidence packs all within your VPC. It transforms ungoverned web access into defensible, traceable research workflows with human-in-the-loop approvals and tamper-evident trails for regulated environments.

October 29, 2025
AI shouldn’t act blindly. Odyssey AI’s Human-in-the-Loop adds intelligent pause points and editable approvals, so agents stay fast on safe steps and pause on risky writes. Leaders get speed, control, and audit-ready evidence without turning workflows into ticket queues.
Get started today
We’ll map your controls, connect a dataset, and stand up a private POC in 1-4 weeks.
.png)
.png)

