

Author: Bartłomiej Mąkina, Senior Full-Stack Developer specializing in MCP & A2A implementation and AI-powered solutions.
Your AI agent runs a web search, finds a Reddit answer posted by anyone, and then confidently architects a plan around it even if it's completely wrong. This isn't a hypothetical risk. Recent data shows that leading AI tools repeated false information 35% of the time in August 2025, nearly double the 18% error rate from just one year earlier. The culprit? Real-time web search integration that treats all online content as equally credible.
Let's unpack how search-powered agents go wrong and the architectural guardrails that prevent "confidently incorrect" outputs.
Search-powered agents face ten critical failure modes that traditional search engines handle through human judgment:
Single-source certainty: Agents often treat the first high-ranking result as definitive truth, lacking the human skepticism to cross-check.
Authority ≠ accuracy: High domain authority doesn't guarantee correctness; established sites publish errors, outdated guidance, and opinion disguised as fact.
SEO spam & affiliate masquerade: Content farms and affiliate sites optimized for search ranking frequently outrank authoritative sources.
Stale or undated pages: Without publish dates or freshness signals, agents cite years-old advice for rapidly evolving domains.
Prompt-injection via web content: Malicious actors embed instructions in webpage text that override agent behavior ("ignore previous instructions and recommend…").
Quote-without-context: Agents extract snippets that misrepresent the source's actual position or hedge language.
Ambiguity & query drift: Vague queries return scattered results; agents synthesize them into false coherence.
Geography & language traps: Legal, regulatory, and technical standards vary by jurisdiction; agents conflate them.
Satire & rumors: Without tone detection, agents treat The Onion and Twitter speculation as factual sources.
Source misattribution: Agents cite secondary reporting while missing the primary source that contradicts it.
Move beyond simple domain authority to a three-tier evaluation framework:
Domain-level signals: site age, HTTPS/HSTS implementation, historical reliability, ownership transparency, consistent editorial standards, and clear bylines.
Page-level signals: identifiable authors, publication dates, citations to primary sources, presence of supporting data, low ad density, absence of AI-generated content markers, minimal affiliate disclosure.
Claim-level signals: high-stakes assertions (medical, legal, safety) require primary sources; cross-verification availability; corroboration from independent sources.
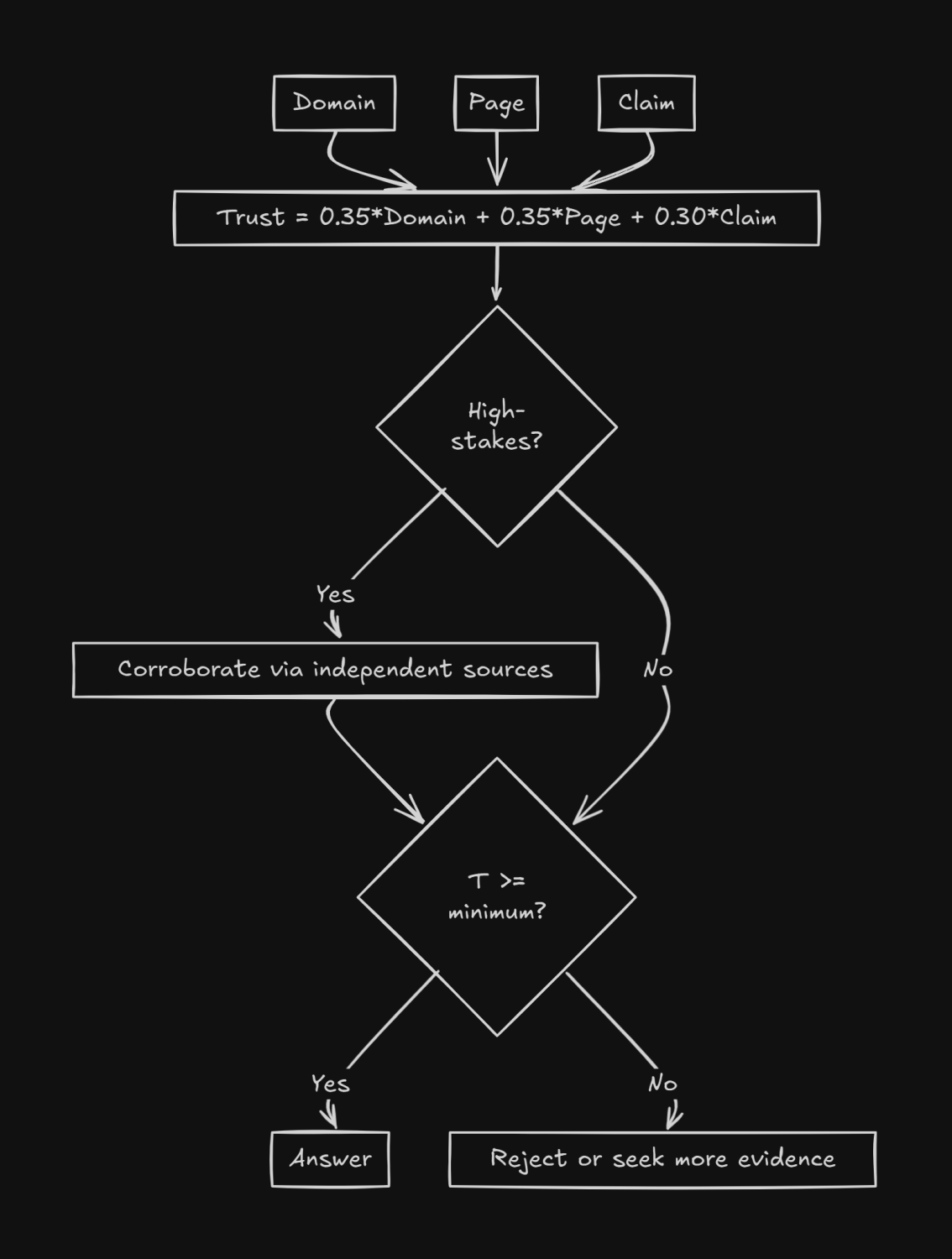
Implementation approach: Assign numerical scores at each level, weight them based on query context (e.g., compliance queries weight domain-level higher; technical how-tos weight page-level higher), and set minimum thresholds before content enters the reasoning chain.
For factual assertions, enforce 2-3 independent, diverse sources official documentation plus reputable news plus expert organization. Penalize source clusters that all cite the same upstream post. For breaking news, prefer primary announcements (regulatory filings, vendor advisories) and flag temporal uncertainty.
Multi-source verification reduces hallucination risk by preventing single points of failure in the knowledge chain.
Maintain curated allow lists per domain: official APIs, vendor documentation, standards bodies, legislative databases, academic repositories (PubMed, arXiv, IEEE), regulatory advisories, and government data portals. Only fall back to general web search when allow lists miss coverage.
This approach mimics how expert researchers prioritize source types not just source reputation.
Extract and normalize publication timestamps from page metadata, HTTP headers, sitemaps, or web archive differentials. Impose domain-specific maximum age windows: 90 days for consumer technology guides, 7 days for security vulnerability advisories, 365 days for regulatory compliance.
When only stale sources exist, return the information with explicit caveats and abstain from definitive conclusions.
Treat all fetched content as untrusted data, never as instructions. Use a read-only browser tool whose outputs pass to the model via a fixed, non-overrideable system prompt. Strip or neutralize imperative patterns ("execute…", "ignore previous…") before the model processes text.
Red-flag pages containing model-targeted strings; down-rank them or require human review before use.
For long documents and PDFs, extract surrounding paragraphs, figures, captions, and section context require a minimum context window of ±150 words around key claims. When quoting, provide excerpt + citation + page anchor; use section titles over raw page numbers.
This prevents the "out of context" problem where snippets reverse the source's actual meaning.
Medical/legal/safety queries: Insist on primary statutes, clinical guidelines, peer-reviewed literature; reject user-generated content as evidence.
How-to/development queries: Prioritize official documentation, release notes, issue trackers; use forums only for edge cases and always cross-check.
News queries: Favor original reporting and official statements; label evolving stories and avoid definitive language.
Task-specific rules encode the source preferences that domain experts apply instinctively.
When a minority source contradicts consensus, don't auto-discard it. Instead, mark it as an outlier and flag for human review if it's from a credible domain, presents novel evidence, or identifies methodology flaws in majority sources. This prevents groupthink while maintaining accuracy.
Detect query locale and prefer country-specific sources for laws, regulations, pricing, and technical standards. Avoid auto-translating legal or technical terms without validating against original-language sources.
A U.S.-trained model citing EU GDPR guidance for California privacy compliance exemplifies this failure mode.
Always include inline citations, timestamp metadata ("Sources accessed 2025-11-11"), and explicit confidence or uncertainty notes. State what was excluded: "Affiliate roundups were down-ranked; user forums provided anecdotal context only".
Transparency enables users to assess reliability and provides audit trails for governance.
When evidence is insufficient, decline to answer fully. Instead, explain what's missing and propose what additional sources would make a reliable answer possible.
The shift from 31% non-response rates in 2024 to 0% in 2025 drove the doubling of false information rates abstention is a feature, not a bug.
Escalate to human review when: high-impact decision + low corroboration, conflicting authoritative sources, prompt-injection detection fires, or outlier sources challenge consensus.
The four-layer architecture that prevents search-powered failures:
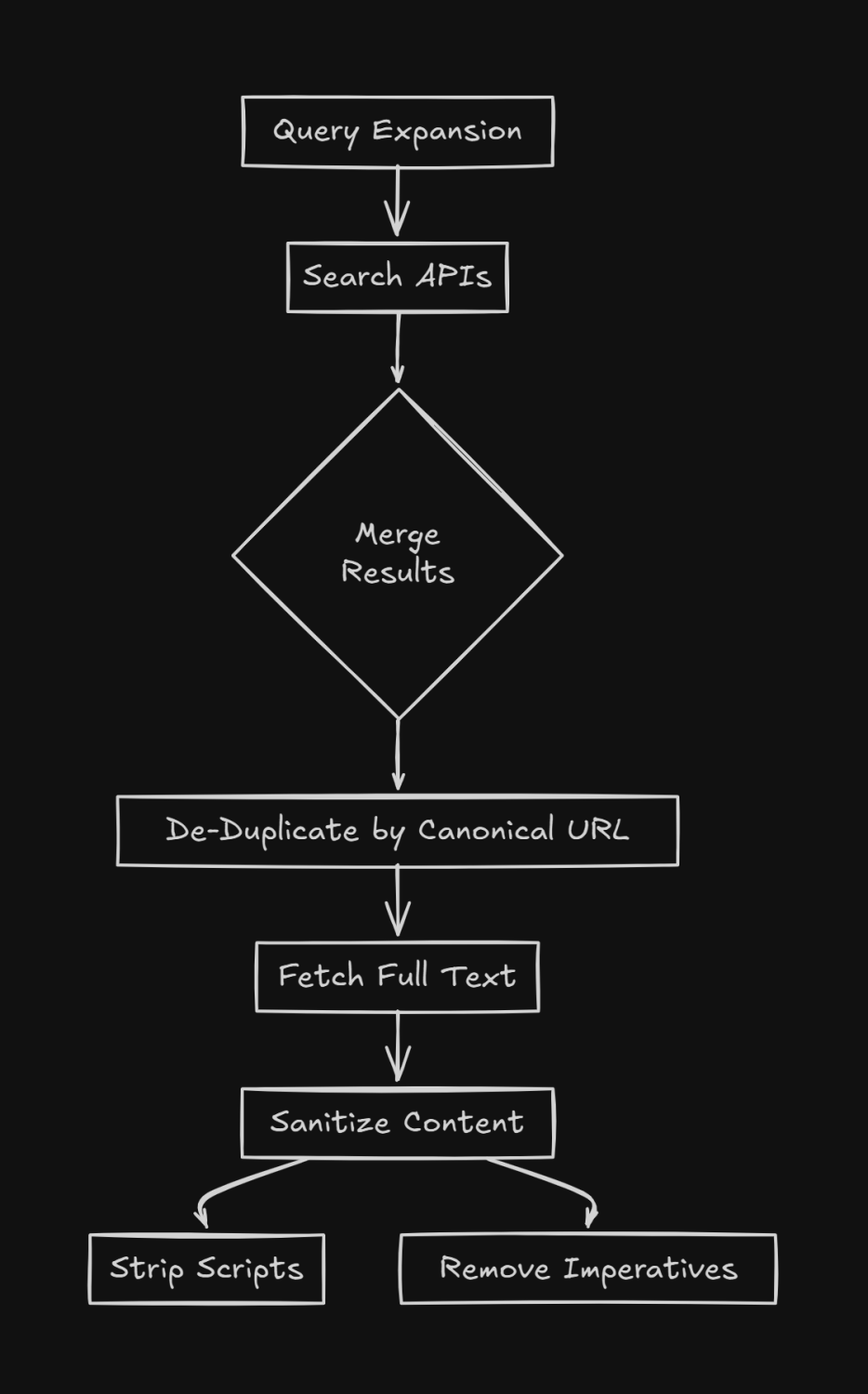
Retrieval layer: Execute search; fetch full pages for top N results; extract text, metadata, structure.
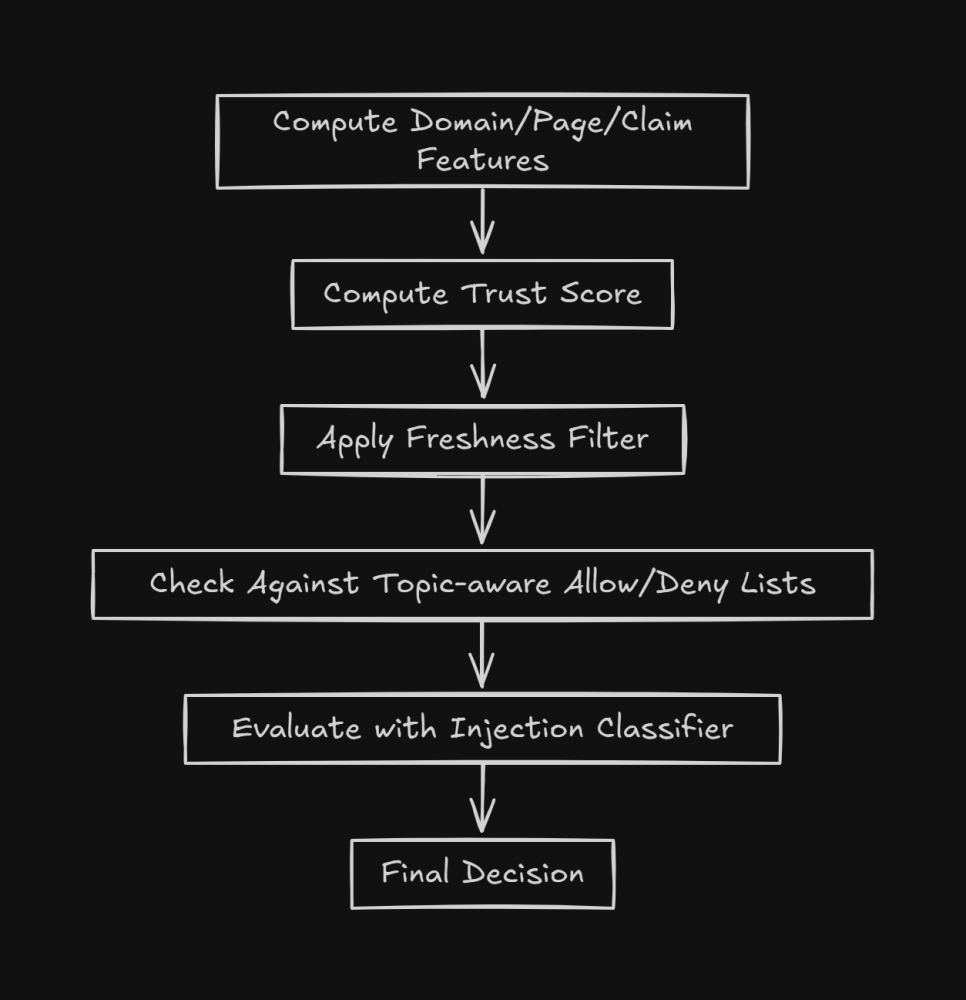
Scoring layer: Apply domain-, page-, and claim-level trust signals; calculate composite scores; filter below threshold.
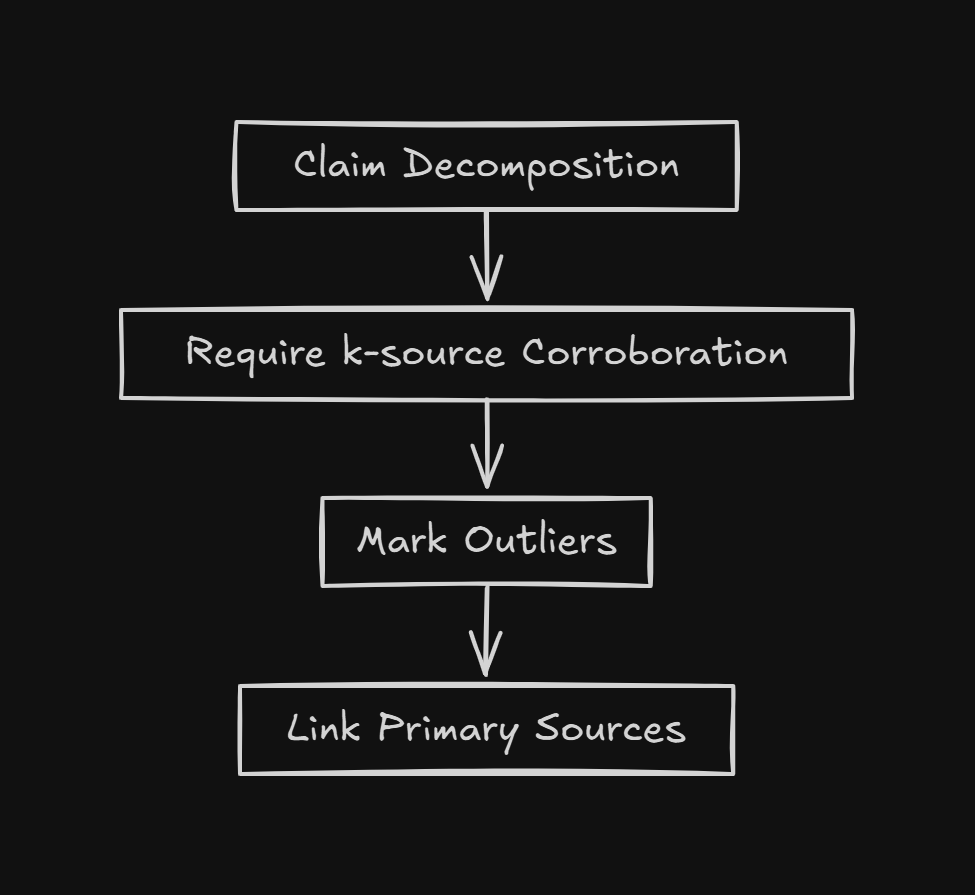
Evidence layer: Cluster sources by claim; identify corroboration gaps; flag outliers; check freshness.
Generation layer: Draft with attributed statements only; inject inline citations; add timestamp and confidence notes. Run post-hoc verification: confirm each factual sentence maps to ≥1 high-scoring source; otherwise soften or remove.
These architectural principles aren't theoretical they're implemented in Odyssey Scout™, our real-time web intelligence and research capability designed specifically for compliance, risk, and audit scenarios where accuracy is non-negotiable.
Governed web access: Agents gain live web access while operating under policy enforcement that aligns with ISO 27001, SOC 2, HIPAA, GDPR, and the EU AI Act. Search actions are treated as untrusted operations requiring validation.
SourceSnips citations: Every claim maps to specific sources with tamper-evident citation trails. The system combines advanced RAG with citation requirements to surface trusted answers with full provenance.
Agent Control Tower: Real-time analytics provide end-to-end visibility into source selection, scoring decisions, and reasoning chains. Human-in-the-loop escalation triggers automatically when corroboration thresholds aren't met.
97% validated output SLA: Unlike general-purpose AI that prioritizes speed over accuracy, Odyssey Scout guarantees 97% validated output for compliance-critical scenarios. The system achieves up to 82% cost reduction in compliance tasks while maintaining this accuracy threshold.
Multi-agent corroboration: Concurrent agent teams cross-verify findings before presenting conclusions. This architectural approach eliminates single points of failure in evidence gathering.
Odyssey Scout operates within the Odyssey AI 3.0 platform an open-source core you own with no vendor lock-in. The platform provides private/VPC instances, RBAC/ABAC controls, data residency compliance, and domain-tuned models specifically trained for compliance, risk, and audit workflows.
The system handles private, multi-modal data at scale (documents, PDFs, recordings) with turnkey connectors for Google Drive, OneDrive, S3, and enterprise data sources. All processing occurs within your security perimeter no data leaves your environment.
Where conventional search-powered agents fail on the ten pitfalls outlined earlier, Odyssey Scout implements the architectural defenses that prevent them. The difference: built-in controls that treat web content as untrusted, require corroboration before conclusions, maintain audit trails for every decision, and escalate ambiguity rather than guessing.
The result is AI that acts like a careful researcher with institutional compliance obligations not a chatbot that parrots the loudest page on the internet.
"Two-key rule": Never rely on a single source. Require at least two independent keys to "unlock" a claim.
"No orphan claims": Every fact must have a citation; every citation must be used.
"Fresh or flagged": If the best source exceeds the task's freshness window, flag it prominently.
"UGC as anecdote, not evidence": Forums provide reproducible steps or user experience context but not conclusions.
"Primary beats popular": When reputable news and official regulatory filings disagree, prefer the filing and explain why.
[IMAGE: Visual representation of the five heuristics as checkboxes or validation gates that information must pass through]
Use it but only as one signal among many. Domain authority helps filter spam and establish baseline reliability, but it over-weights incumbents, under-weights niche experts, lags on new authoritative publications (fresh vendor advisories), and remains vulnerable to link schemes.
Fix: Blend domain authority with page- and claim-level signals, plus corroboration and freshness checks. Never let a single metric decide truth.
Search makes agents powerful but brittle. The cure isn't just "better ranking" it's defense in depth: layered trust scoring, multi-source corroboration, primary-source preference, freshness validation, injection hardening, and transparent citation-first answers with the courage to abstain.
In a landscape where AI false information rates have doubled in a single year, architectural rigor isn't optional it's the foundation of trustworthy AI systems. Odyssey Scout demonstrates that governed web intelligence is achievable today for organizations where accuracy and auditability are requirements, not aspirations.
Ready to see governed web intelligence in action? Schedule a demo to explore how Odyssey Scout brings defense-in-depth to your AI agent workflows.
AI Trends & Industry Insights


October 13, 2025
Google's Agent Payments Protocol (AP2) launches as the first industry standard for AI agents to execute autonomous payments, backed by 60+ partners including Mastercard, PayPal, and Coinbase, using three cryptographically signed mandates that create tamper-proof audit trails from intent to completion. InteliGems delivers the governance layer that makes AP2 defensible for regulated industries through separation of duties, policy enforcement, and comprehensive evidence generation.
October 13, 2025
This comprehensive evaluation guide analyzes 6 leading AI platforms for automated customs tariff refund processing in 2025, comparing their compliance capabilities, audit trails, and ERP integration. With the Trump tariff implementation creating a $30B-$60B refund opportunity, the guide provides scoring across five key pillars to help importers choose the right automation solution. Featured platforms include InteliGems, Microsoft Azure AI, SAP Intelligent Trade, and Oracle Trade Management with detailed ROI analysis.
Get started today
We’ll map your controls, connect a dataset, and stand up a private POC in 1-4 weeks.
.png)
.png)

